I was invited to speak at the Seattle Technical Forum’s first “Big Data Deep Dive”. The event was very well organized and all three presentations dove-tailed into each other quite well. No recording was made of the event, so this is a transcription of my talk based on notes and memory.
The deck is available on slideshare, and embedded at the bottom of the post.

Hi everyone, thanks for having me. My name is Nick Dimiduk, I’m an engineer on the HBase team at Hortonworks, contributing code and advising our customers on their HBase deployments. I’m also an author of HBase in Action on Manning Press, a book I’m hoping will serve as the unofficial user’s guide to HBase. I’ve been using HBase since 2008, so quite a long time, considering the project was first released in 2007.
For this talk tonight, I want to provide an “architect’s overview” of HBase, meaning I’m going to make some claims about what HBase is and isn’t good at, and then defend those claims with details of HBase internals. This is a “deep dive,” after all. In addition to high-level design, I’ll get into some details of the storage machinery behind HBase. My slot is only 30 minutes, so we’ll see how far I can get.
I don’t usually include a users slide like this one and I won’t linger. However, I think it’s useful to point out the increasing HBase adoption we’re seeing, and this is a simple way to do that. Way back when I started using HBase, this slide would have had only two or three logos. The project has come a long way and I credit that to the active community that has formed around HBase. When I decided to introduce HBase to my first organization, we couldn’t afford any of the vendor solutions on the market, but I still had to make a pitch for a young open source project. The community was a big part of the confidence I had in making that decision and advocating it to management.
For a quick agenda, I want to briefly describe the context for HBase and then dive right into its implementation. I’ll go over the logical architecture and data model, and then we’ll dig into the RegionServer internals. The summary section is less a summary of the topics covered, but rather an outline of conclusions to be drawn from them. The final bits are to provide you with follow-up resources so you can continue with HBase when you get home. If there are no questions, let’s get started.
People talk about Apache Hadoop as a single tool, but it’s actually composed of two fundamental parts. The Hadoop Distributed Filesystem (HDFS), provides distributed, redundant storage. HDFS uses the filesystem analogy rather than the table analogy used by databases. It presents a directory structure with files, user permissions, &c. It’s optimized for high throughput of large data files – in a filesystem, files are composed of storage blocks on disk. In the usual desktop filesystems like ext3, the block size is on the order of 4k. HDFS has a default blocksize of 64mb.
The other Hadoop component is Hadoop MapReduce. MapReduce is the computational framework that builds on HDFS. It provides a harness for writing applications that run across a cluster of machines and a runtime for managing the execution of those applications. Its operation is batch-oriented – it sacrifices latency for throughput and is designed to compliment the features of HDFS. MapReduce applications are generally line- or record-oriented. Both HDFS and MapReduce are open source implementations of the data storage and computation systems described by papers published by Google almost 10 years ago. When people talk about Hadoop, they’re usually talking about MapReduce and implying use of HDFS. This article has a great overview of MapReduce and its applications.
HBase is a database that sits on top of the HDFS and enjoys tight MapReduce integration. Like HDFS and MapReduce, it’s based on a technology described in a Google paper; that technology is called BigTable.
Just like the databases we’re used to, HBase exposes a data model consisting of tables containing rows, with data within those rows organized into columns. That’s basically where the similarities end. From the web page, it’s designed to manage big tables, billions of rows with millions of columns. HBase is a “schemaless” database, meaning you don’t have to tell it ahead of time what columns a table will contain.
HBase is a distributed database – it’s designed to run across a fleet of computers rather than a single machine. It provides for splitting up those tables of billions of rows and distributing them across the cluster. If you have any experience with partitioning a relational database, this should come as music to your ears (as it did for me!)
Fantastic. How does HBase provide all this – and, what exactly does it provide? Let’s start by having a look at a Big Table.
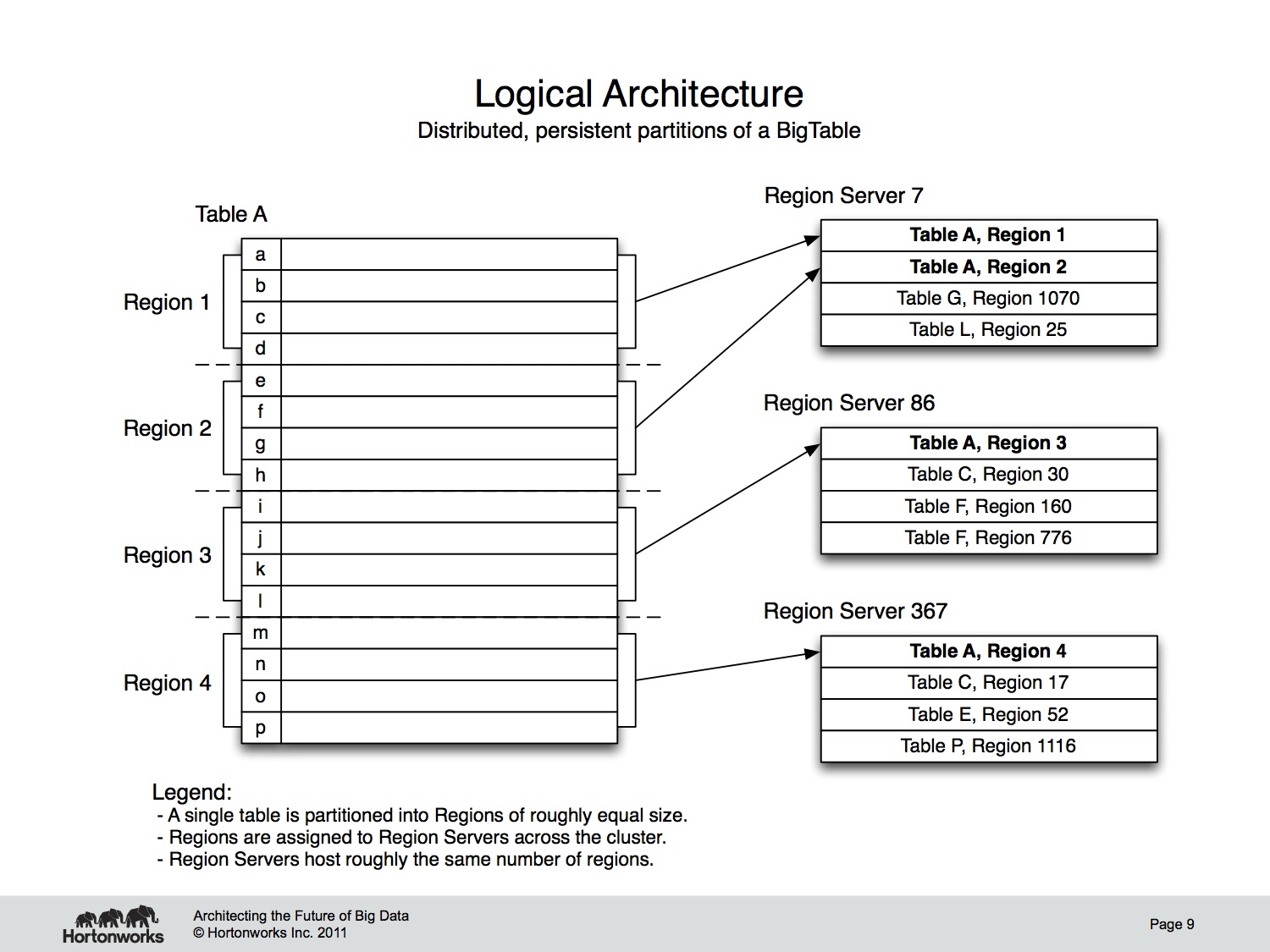
This is the logical architecture exposed by HBase. Data stored in the “big table” is located by it’s “rowkey.” This is like a primary key from a relational database. Records in HBase are stored in sorted order according to rowkey. This is a fundamental tenant of HBase and is also a critical semantic used in HBase schema design. HBase schema design really comes down to optimizing use of that rowkey.
Continuous sequences of rows are divided into “Regions”. These Regions are then assigned to the worker machines in the cluster, conveniently called “RegionServers”. Assignment and distribution of Regions to RegionServers is automatic and largely hands-off for the operator. There are times when you’ll want to manually manage Regions – HBase will let you do that – but this is not the common case. When data is inserted into a Region and the Region’s size reaches a threshold, the Region is split into two child Regions. The split happens along a rowkey boundary; rows are never divided and a single Region always hosts an entire row. This is another important semantic HBase provides for its users.
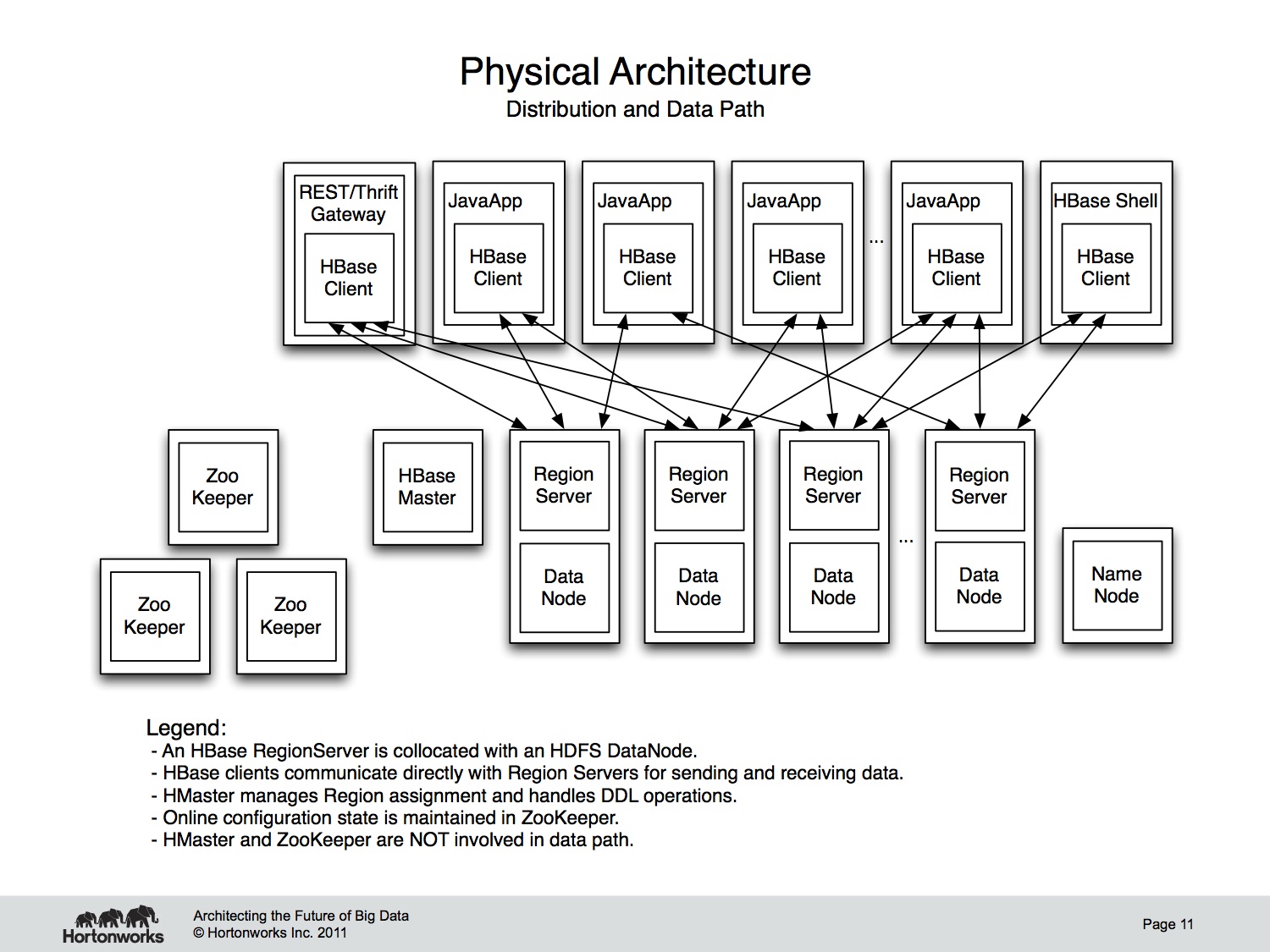
Physically, HBase is composed of a couple components. First, HBase depends on HDFS for data storage. RegionServers collocate with the HDFS DataNodes. This enables data locality for the data served by the RegionServers, at least in the common case. Region assignment, DDL operations, and other book-keeping facilities are handled by the HBase Master process. It uses Zookeeper to maintain live cluster state. When accessing data, clients communicate with HBase RegionServers directly. That way, Zookeeper and the Master process don’t bottle-neck data throughput. No persistent state lives in Zookeeper or the Master. HBase is designed to recover from complete failure entirely from data persisted durably to HDFS. Any questions so far?
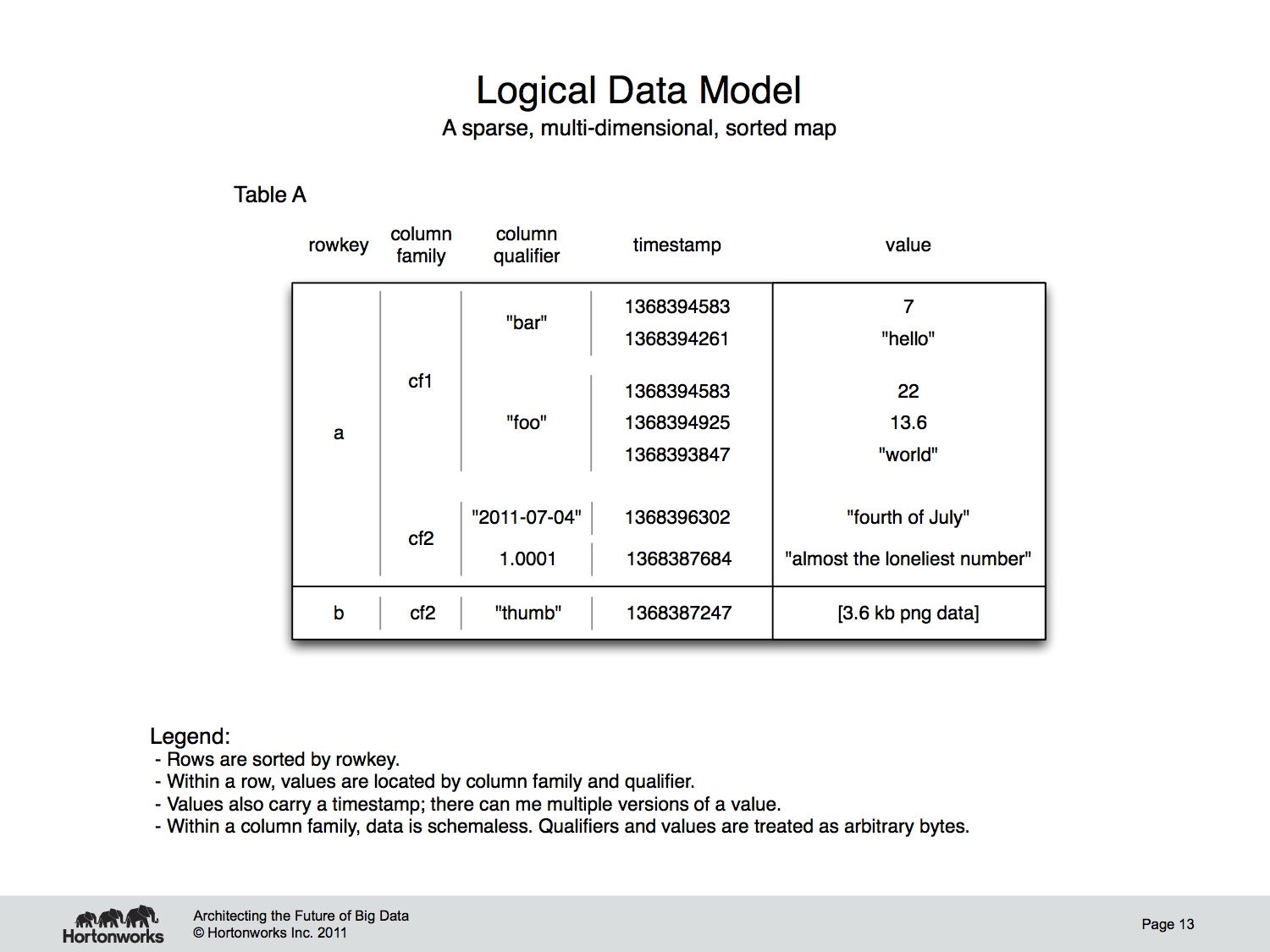
That’s what the cluster looks like, so what does the data look like? An HBase table is presented to users as a sorted map of maps. Think OrderedDictionary from .NET or a TreeMap in Java. Data is accessed by coordinates. From the outside in, those coordinates are: rowkey, column family, column qualifier, and timestamp. Those coordinates together consist are the “key” in HBase’s “key-value pairs”. HBase provides basic key-value operations over the persisted data, GET, PUT, and DELETE. Queries in HBase are implemented by a rowkey SCAN operation. Remember, table data is ordered by rowkey; this is HBase schema design. There are also a couple server-side operations for data manipulation without the extra network call: INCREMENT, APPEND, CheckAndPut, and CheckAndDelete. These operations can cause contention, so use them wisely.
Notice what’s missing. HBase provides no indices over arbitrary columns, no joins, and no multi-row transactions. If you want to query for a row based on it’s column value, you’d better maintain a secondary index for that, or be prepared for a full table scan.
HBase is “column family oriented.” Data is stored physically into column family groups. That means all key-values for a given column family are stored together in the same set of files. This is not the same as a columnar database. Don’t let the similar names confuse you.
Now that you’ve seen what HBase provides, let’s have a look at how it works. This is a “deep dive” after all.
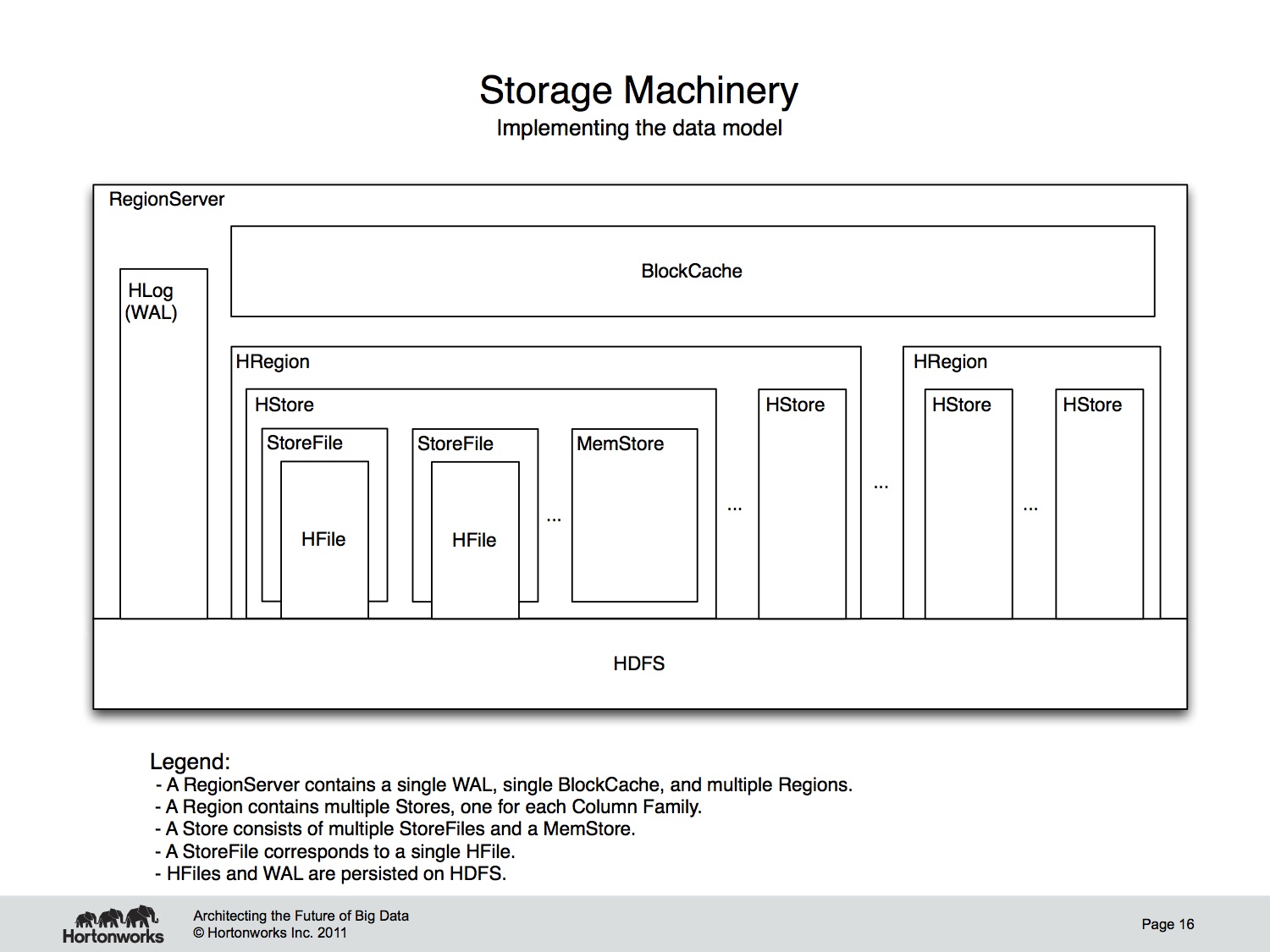
RegionServers encapsulate the storage machinery in HBase. As you saw in the architectural diagram, they’re collocated with the HDFS DataNode for data locality. Every RegionServer has two components shared across all contained Regions: the HLog and the BlockCache. HLog, also called the Write-ahead log, or WAL, is what provides HBase with data durability in the face of failure. Every write to HBase is recorded in the HLog, written to HDFS. The BlockCache is the portion of memory where HBase caches data read off of disk between reads. It’s also a major source of operational headache for HBase when configured to be too large. If you hear about HBase GC configuration woes, they stem largely from this component.
As you saw earlier, RegionServers host multiple Regions. A Region consists of multiple “Stores.” Each Store is corresponds to a column family from the logical model. Remember that business of HBase being a column family oriented database? These Stores provide that physical isolation. A Store consists of multiple StoreFiles plus a MemStore. Data resident on disk is managed by the StoreFiles and is maintained in the HFile format. The MemStore accumulates edits and once filled is flushed to disk, creating new HFiles. An astute observer will notice that this structure is basically a Log-Structured Merge Tree with the MemStore acting as C0 and StoreFiles as C1.
Okay, so now that we understand the essential data architecture, what does that tell us about using HBase? For what kinds of workloads is HBase well suited? I’m going to dance around this question a little bit and say “it depends on how you configure it.” In general though, HBase is designed for large datasets, large enough to span multiple hundreds of machines. The distributed architecture means it does well with lots of concurrent clients. It’s key-value storage machinery make it decent for handling sparse datasets. The lack of joins means it’s best for denormalized schema with loosely-coupled records.
How does HBase integrate into my existing architecture? That depends as well, but less on HBase and more on you. If you’re an application architect type, HBase looks like a horizontally scalable, low-latency, strongly consistent data storage system. It’s the place where you want to throw all your messy application state to keep your application servers as stateless and replaceable as possible. If you’re responsible for a modern, Hadoop-driven data warehouse, you’ll see HBase as a staging area to receive online data streams or as a place to host views of stored data for serving to applications. Essentially, it’s the glue between the batch-oriented MapReduce and online reporting application worlds.
What semantics does HBase provide? These are covered earlier, but in summary, you get a set of key-value operations. The sorted rowkey business provides you a measure of control over how data is stored so that you can optimize for how you want data retrieved. The other thing I didn’t speak to directly is the MapReduce integration. HBase offers MR access to via it’s online API as well as support for bulkloads. Additionally, there will soon be support for running MapReduce jobs over data in HBase snapshots.
How about operational concerns? The biggest thing to remember when provisioning hardware for HBase is that HBase is a low-latency, online database and that it’s IO hungry. I know the manufacturers of magnetic media are trying to entice you with their massive 2+TB drives, but those are not a great plan for HBase. Iops are the name of the game and generally that means you want to maximize your spindles-to-TB ratio. That said, it depends on your application use case and configuration.
For read-heavy applications, you’re balancing between random-access and sequential access patterns. That means tweaking Block size, BlockCache, compression, and data encodings. For writes, you need to balance resources between receiving new data and lifecycle management of existing data. All this is in contention with serving reads. You’ll be considering compaction frequency, region sizes, and possibly region distribution based on your application’s write patterns.
I’ve included links in the slides to some decent blog posts that break down the configuration tuning process. Hopefully that’ll help you get a feel for what’s involved.
No HBase presentation would be complete without a shoutout to the community. Check out the official blog and the mailing lists for loads of information and people interested in helping out. Dive into IRC if you’re that flavor of neck-beard. All HBase development happens on the Apache JIRA. If you’re feeling stalkerish, you can check out my JIRA profile and see what I’ve been up to recently. The best way to meet the community is to go out and meet them. Locally, there’s the Seattle Scalability meetup that’s been around for quite a while. Summer is conference season, so you can also jet down to CA to check out both HBaseCon and Hadoop Summit.

Finally, here’s a short summary of the work we’ve been doing on the HBase team at Hortonworks. Notably, we’re working hard to minimize the time for failure recovery. You may also be interested in our work on getting HBase up and running on Windows.
That’s about all I have for you. You can find me on the web, on twitter, and on github. Thanks for listening!